> For the complete documentation index, see [llms.txt](https://tomthestrom.gitbook.io/cs61b-fall-2022/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://tomthestrom.gitbook.io/cs61b-fall-2022/project-2b-ngordnet-wordnet.md).
# Project 2b: NGordNet (WordNet)
WordNet[Prerequisites](/cs61b-fall-2022/prerequisites-to-running-the-assignments..md) to running the code. Additionally, you need to [download the data files](https://drive.google.com/file/d/1xGTZqCo5maiZjA307OPocmKDOTYlJXnz/view?usp=sharing).
Instructions:
Solution:
## About the project
Great project without too many instructions on how to do it.
Included:
1. [Designing & Implementing a Directed Acyclic Graph](#challenge-1-coming-up-with-a-design-for-the-supporting-graph) with an adjacency list.
2. Implementing lookups to support the functionality of the Graph.
3. [Using a Max Heap and implementing a way to compare the popularity of words within a certain time period](#challenge-3-handling-k-greater-than-0).
4. [Writing unit tests to verify correctness.](#tests)
### Using the WordNet Dataset [#](https://fa22.datastructur.es/materials/proj/proj2b/#using-the-wordnet-dataset)
Before we can incorporate WordNet into our project, we first need to understand the WordNet dataset.
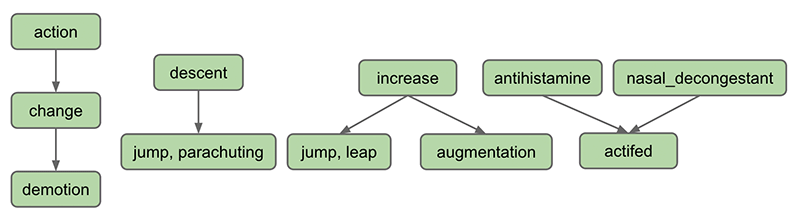
[WordNet](http://en.wikipedia.org/wiki/WordNet) is a “semantic lexicon for the English language” that is used extensively by computational linguists and cognitive scientists; for example, it was a key component in IBM’s Watson. WordNet groups words into sets of synonyms called synsets and describes semantic relationships between them. One such relationship is the is-a relationship, which connects a **hypo**nym (more specific synset) to a **hyper**nym (more general synset). For example, “change” is a **hypernym** of “demotion”, since “demotion” is-a (type of) “change”. “ change” is in turn a **hyponym** of “action”, since “change” is-a (type of) “action”. A visual depiction of some hyponym relationships in English is given below:
Each node in the graph above is a **synset**. Synsets consist of one or more words in English that all have the same meaning. For example, one synset is [“jump, parachuting”](http://wordnetweb.princeton.edu/perl/webwn?o2=\&o0=1\&o8=1\&o1=1\&o7=\&o5=\&o9=\&o6=\&o3=\&o4=\&s=jump\&i=6\&h=000010000000000000000000#c) , which represents the act of descending to the ground with a parachute. “jump, parachuting” is a hyponym of “descent”, since “jump, parachuting” is-a “descent”.
Words in English may belong to multiple synsets. This is just another way of saying words may have multiple meanings. For example, the word “jump” also belongs to the synset [“jump, leap”](http://wordnetweb.princeton.edu/perl/webwn?o2=\&o0=1\&o8=1\&o1=1\&o7=\&o5=\&o9=\&o6=\&o3=\&o4=\&s=jump\&i=2\&h=100000000000000000000000#c) , which represents the more figurative notion of jumping (e.g. a jump in attendance) rather the literal meaning of jump from the other synset (e.g. a jump over a puddle). The hypernym of the synset “jump, leap” is “increase”, since “jump, leap” is-an “increase”. Of course, there are other ways to “increase” something: for example, we can increase something through “augmentation,” and thus it is no surprise that we have an arrow pointing downwards from “increase” to “augmentation” in the diagram above.
Synsets may include not just words, but also what are known as [collocations](http://en.wikipedia.org/wiki/Collocation). You can think of these as single words that occur next to each other so often that they are considered a single word, e.g. [nasal\_decongestant](http://wordnetweb.princeton.edu/perl/webwn?s=nasal+decongestant+\&sub=Search+WordNet\&o2=\&o0=1\&o8=1\&o1=1\&o7=\&o5=\&o9=\&o6=\&o3=\&o4=\&h=) . To avoid ambiguity, we will represent the constituent words of collocations as being separated with an underscore \_ instead of the usual convention in English of separating them with spaces. For simplicity, we will refer to collocations as simply “words” throughout this document.
A synset may be a hyponym of multiple synsets. For example, “actifed” is a hyponym of both “antihistamine” and “ nasal\_decongestant”, since “actifed” is both of these things.
If you’re curious, you can browse the Wordnet database by [using the web interface](http://wordnetweb.princeton.edu/perl/webwn?o2=\&o0=1\&o8=1\&o1=1\&o7=\&o5=\&o9=\&o6=\&o3=\&o4=\&r=1\&s=sturgeon\&i=3\&h=1000#c) , though this is not necessary for this project.
## Challenges, Description, Implementation
I decided to divide this section into the most significant challenges I faced.
### Challenge 1 - Coming up with a design for the supporting graph
#### Description
**The first challenge was coming up with a design for a Graph** to support the requested operations. The data was provided in 2 types of text files:
* File type #1: List of noun synsets. The file `synsets.txt` (and other smaller files with synset in the name) lists all the synsets in WordNet. **The first field is the synset id** (an integer), t**he second field is the synonym set (or synset)** , and **the third field is its dictionary definition** (also called its “gloss” for some reason). For example, the line
```
36,AND_circuit AND_gate,a circuit in a computer that fires only when all of its inputs fire
```
* means that the synset `{ AND_circuit, AND_gate }` has an id number of 36 and its definition is “a circuit in a computer that fires only when all of its inputs fire”. The individual nouns that comprise a synset are separated by spaces (and a synset element is not permitted to contain a space). The S synset ids are numbered 0 through S − 1; the id numbers will appear consecutively in the synset file. You will not (officially) use the definitions in this project, though you’re welcome to use them in some interesting way if you’d like if you decide to add optional features at the end of this project. The id numbers are useful because they also appear in the hyponym files, described as file type #2.
* File type #2: List of hyponyms. The file `hyponyms.txt` (and other smaller files with hyponym in the name) contains the hyponym relationships: The first field is a synset id; subsequent fields are the id numbers of the synset’s direct hyponyms. For example, the following line
```
79537,38611,9007
```
means that the synset 79537 (“viceroy vicereine”) has two hyponyms: 38611 (“exarch”) and 9007 (“Khedive”), representing that exarchs and Khedives are both types of viceroys (or vicereine). The synsets are obtained from the corresponding lines in the file `synsets.txt`:
```
79537,viceroy vicereine,governor of a country or province who rules...
38611,exarch,a viceroy who governed a large province in the Roman Empire
9007,Khedive,one of the Turkish viceroys who ruled Egypt between...
```
There may be more than one line that starts with the same synset ID. For example, in `hyponyms16.txt`, we have
```
11,12
11,13
```
This indicates that both synsets 12 and 13 are direct hyponyms of synset 11. These two could also have been combined on to one line, i.e. the line below would have the exact same meaning, namely that synsets 12 and 13 are direct hyponyms of synset 11.
```
11,12,13
```
You might ask why there are two ways of specifying the same thing. Real world data is often messy, and we have to deal with it.
#### Implementation
if we "remove" all the "noise", the data provided by the instructors was basically in 2 formats.
The first was a "map" an **`Integer`** ID associated with a **`String`** word.
The second was already sort of a "graph" since it provided an adjacency list in a form of an **`Integer`** **ID** as a **parent/hypernym** and an **`Integer`** **list** of 1 or more of it's **children/hyponyms.** I used an [**`IdToIdsMap>`**](#class-idtoidsmap) within the [**`Graph`**](#class-graph) class to store these relationships**.**
I proceeded by creating a [**`WordNet`**](#class-wordnet) `class` which would act as an **intermediary** between the only **required class in this exam** - [**`HyponymHandler`**](#class-hyponymhandler) - the class that handles queries from the frontend and the **`Graph`** `class`, for which **`WordNet`** acts as a **wrapper**.
In order **to support lookup by words provided by the user** and to be able **to use the results of the lookup** (all the ids associated with the word) **to query the Graph**, I implemented 2 **`HashMaps`** that acted as instance properties of the **`WordNet`** class:
1. A `HashMap` [**`WordToIdsMap>`**](#class-wordtoidsmap)**`:`**
Upon lookup returns a **`HashSet`** of **ids associated with the requested word**, so that we can look them up in the **`Graph`**.
2. A `HashMap` of [**`IdToWordsMap>`**](#class-idtowordsmap):
Upon lookup returns a **`HashSet`** of **words associated with the requested id**, so that we can associate the results returned by querying the **`Graph`** with actual words.
### Challenge 2 - Handling List of Words
#### Description
More verbose description:
Based on the [description of the Graph functionality in Challenge nr 1](#challenge-nr-1-implementation-coming-up-with-a-design-for-the-supporting-graph), it's not hard to understand how retrieving hyponyms for one hypernym works (check **`WordNet`** - **`getHyponyms`** method for the exact implementation).
The challenge of handling a list of words layed in only returning words that are the hyponyms of all of the provided (the list) hypernyms. If the user types “**female, animal**” in the words box. Then, clicking “Hyponyms” should display *\[amazon, bird, cat, chick, dam, demoiselle, female, female\_mammal, filly, hag, hen, nanny, nymph, siren]*, as **these are all the words which are hyponyms of female and animal**.
#### Implementation
I implemented this in **`WordNet`** - **`getHyponymsIntersect`**, where I first call the **`getHyponyms`** method for each word on the list, save each result in a `TreeSet`. These `TreeSets` are stored in an `array` which I iterate over and use [**`retainAll`**](https://www.javatpoint.com/java-arraylist-retainall-method) to determine which words (hyponyms) appear in all `TreeSets`.
The result is then returned to the user.
### Challenge 3 - Handling k > 0
#### Description
The methods implemented in the previous challenges returned as many "proper" results as possible. However - what if the user wanted to specify the maximum amount of words they're interested in? In that case, I have to find a way to return the the top k most popular words (possibly in a certain time period).
#### Implementation
To get the k most popular hyponyms of a hypernym (possibly a list of hypernyms), I implemented the **`getKPopularHyponyms`** method in **`WordNet`** `class`.
**`getKPopularHyponyms`**
* uses a **`MaxPQ`** for sorting the hyponyms by popularity (weight) via **`WordNet`** - **`getWordWeightPQ`**
* [**`WordWeight`**](#public-record-wordweight) is a **`public record`** with 2 props - `String` **`word`** and `Double` **weight**
* implements **`Comparable`** interface - **`compareTo`** uses the **`weight`** **property for comparison**
* is the method that is ultimately used to handle all the requests (called in `HyponymHandler.handle`)**,** be it 1 or a list of hypernyms**,** a k = 0 or a k > 0**.**
* The data flow is such as:
HyponymHandler.handle => Wordnet.getKPopularHyponyms()
## Summary
Those were the most challenging parts of the project, with the most challenging being designing a proper structure to represent the **Directed Acyclic Graph** that would represent the relationship between the *hypernyms* and *hyponyms*.
The only required part of the project was the `HyponymHandler` class and its `handle` method. The rest was to be decided by the students.
Extensive unit test were provided to test the `HyponymHandler` handle method and I also wrote some unit tests for the classes I implemented to verify their correctness.
### Tests:
All tests can be found here: . Additionally I'm linking the specific unit test I implemented above the code of each class.
### Class HyponymHandler
Extensive tests for this class had already provided (see link above).
```java
package ngordnet.main;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import edu.princeton.cs.algs4.In;
import edu.princeton.cs.algs4.MaxPQ;
import ngordnet.ngrams.NGramMap;
public class WordNet {
//wrapper for a graph
/**
* Keeps track of the ids associated with the word
*/
private WordToIdsMap wordToIdsMap;
/**
* Keeps track of the words associated with the id
*/
private IdToWordsMap idToWordsMap;
/**
* Keeps track of id to id connection hypernym -> hyponym
*/
private Graph graph;
public WordNet(String synsetsFileName, String hyponymsFileName) {
graph = new Graph();
wordToIdsMap = new WordToIdsMap();
idToWordsMap = new IdToWordsMap();
setMapsFromFile(synsetsFileName);
setGraphFromFile(hyponymsFileName);
}
/**
* Returns all the hyponyms of the hypernym, including the hypernym itself - in order thx to being a TreeSet
* @param hypernym
*/
public TreeSet getHyponyms(String hypernym) {
HashSet parentIds = wordToIdsMap.get(hypernym);
HashSet childIds = new HashSet<>();
TreeSet hyponyms = new TreeSet<>();
for (int parentId : parentIds) {
//find and get all child ids from the graph
childIds.addAll(graph.getAllChildren(parentId));
//add all words associated with the parent ids to hyponyms set
hyponyms.addAll(idToWordsMap.get(parentId));
}
for (int childId : childIds) {
//add all words associated with the found child ids to hyponyms set
hyponyms.addAll(idToWordsMap.get(childId));
}
return hyponyms;
}
/**
* Returns the hyponyms that are common between all requested hypernyms (sets intersection)
* @param hypernyms
*/
public TreeSet getHyponymsIntersect(List hypernyms) {
TreeSet hyponyms;
TreeSet[] hyponymsSets = new TreeSet[hypernyms.size()];
//create hypernyms.size() amount of hyponyms sets
for (int i = 0; i < hypernyms.size(); i++) {
hyponymsSets[i] = getHyponyms(hypernyms.get(i));
}
if (hyponymsSets[0] == null) {
hyponyms = new TreeSet<>();
} else {
//init hyponyms with the value of the 0th set
hyponyms = hyponymsSets[0];
}
//iterate over the rest of hyponyms sets - removing items not found in the other ones
for (int i = 1; i < hyponymsSets.length; i++) {
if (hyponymsSets[i] != null) {
hyponyms.retainAll(hyponymsSets[i]);
}
}
return hyponyms;
}
/**
* Returns k most popular hyponyms between years
*/
public TreeSet getKPopularHyponyms(NGramMap ngramMap, List hypernyms, int k, int startYear, int endYear) {
TreeSet requestedHyponyms = getHyponymsIntersect(hypernyms);
if (k <= 0) {
return requestedHyponyms;
}
TreeSet kPopularHyponyms = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
MaxPQ maxPQ = getWordWeightPQ(ngramMap, requestedHyponyms, startYear, endYear);
Iterator iterator = maxPQ.iterator();
int i = 0;
while (iterator.hasNext() && i < k) {
kPopularHyponyms.add(iterator.next().word());
i++;
}
return kPopularHyponyms;
}
private void addWordToMap(String word, Integer id) {
wordToIdsMap.addWordIdPair(word, id);
idToWordsMap.addIdWordPair(id, word);
}
private HashSet getWordIdSet(String word) {
return wordToIdsMap.get(word);
}
private HashSet getIdWordSet(int id) {
return idToWordsMap.get(id);
}
/**
* Sets both word to ids and ids to word mappings from the provided synsets.txt file
* @param fileName
*/
private void setMapsFromFile(String fileName) {
In in = new In(fileName);
ArrayList line;
int id;
while (in.hasNextLine()) {
line = Stream.of(in.readLine().split(",")).collect(Collectors.toCollection(ArrayList::new));
id = Integer.parseInt(line.get(0));
String[] words = (line.get(1)).trim().split("\\s+");
for (String word: words) {
addWordToMap(word, id);
}
}
}
/**
* Sets id to id mappings from the provided hyponyms.txt
* @param fileName
*/
private void setGraphFromFile(String fileName) {
In in = new In(fileName);
ArrayList line;
int parentId;
while (in.hasNextLine()) {
line = Stream.of(in.readLine().split(",")).collect(Collectors.toCollection(ArrayList::new));
parentId = Integer.parseInt(line.get(0));
for (int i = 1; i < line.size(); i++) {
int childId = Integer.parseInt(line.get(i));
graph.addNode(parentId, childId);
}
}
}
/**
* Returns a PQ of k amount of WordWeight objects - weight is based on their popularity in NgramMap
* between the given years
*/
private MaxPQ getWordWeightPQ(NGramMap nGramMap, Collection words, int startYear, int endYear) {
MaxPQ maxPQ = new MaxPQ<>();
for (String word : words) {
/*
* nMap - summedWHistory only takes lists as arg
* returns a timeseries year -> sum
* data() of timeseries returns the sums
* .stream().mapToDouble().sum() to get the total sum
*/
double weight = nGramMap.summedWeightHistory(Collections.singletonList(word), startYear, endYear)
.data()
.stream()
.mapToDouble(Double::doubleValue).sum();
WordWeight wordWeight = new WordWeight(word, weight);
maxPQ.insert(wordWeight);
}
return maxPQ;
}
}
```
### Class WordNet
Unit test:
```java
package ngordnet.main;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import edu.princeton.cs.algs4.In;
import edu.princeton.cs.algs4.MaxPQ;
import ngordnet.ngrams.NGramMap;
public class WordNet {
//wrapper for a graph
/**
* Keeps track of the ids associated with the word
*/
private WordToIdsMap wordToIdsMap;
/**
* Keeps track of the words associated with the id
*/
private IdToWordsMap idToWordsMap;
/**
* Keeps track of id to id connection hypernym -> hyponym
*/
private Graph graph;
public WordNet(String synsetsFileName, String hyponymsFileName) {
graph = new Graph();
wordToIdsMap = new WordToIdsMap();
idToWordsMap = new IdToWordsMap();
setMapsFromFile(synsetsFileName);
setGraphFromFile(hyponymsFileName);
}
/**
* Returns all the hyponyms of the hypernym, including the hypernym itself - in order thx to being a TreeSet
* @param hypernym
*/
public TreeSet getHyponyms(String hypernym) {
HashSet parentIds = wordToIdsMap.get(hypernym);
HashSet childIds = new HashSet<>();
TreeSet hyponyms = new TreeSet<>();
for (int parentId : parentIds) {
//find and get all child ids from the graph
childIds.addAll(graph.getAllChildren(parentId));
//add all words associated with the parent ids to hyponyms set
hyponyms.addAll(idToWordsMap.get(parentId));
}
for (int childId : childIds) {
//add all words associated with the found child ids to hyponyms set
hyponyms.addAll(idToWordsMap.get(childId));
}
return hyponyms;
}
/**
* Returns the hyponyms that are common between all requested hypernyms (sets intersection)
* @param hypernyms
*/
public TreeSet getHyponymsIntersect(List hypernyms) {
TreeSet hyponyms;
TreeSet[] hyponymsSets = new TreeSet[hypernyms.size()];
//create hypernyms.size() amount of hyponyms sets
for (int i = 0; i < hypernyms.size(); i++) {
hyponymsSets[i] = getHyponyms(hypernyms.get(i));
}
if (hyponymsSets[0] == null) {
hyponyms = new TreeSet<>();
} else {
//init hyponyms with the value of the 0th set
hyponyms = hyponymsSets[0];
}
//iterate over the rest of hyponyms sets - removing items not found in the other ones
for (int i = 1; i < hyponymsSets.length; i++) {
if (hyponymsSets[i] != null) {
hyponyms.retainAll(hyponymsSets[i]);
}
}
return hyponyms;
}
/**
* Returns k most popular hyponyms between years
*/
public TreeSet getKPopularHyponyms(NGramMap ngramMap, List hypernyms, int k, int startYear, int endYear) {
TreeSet requestedHyponyms = getHyponymsIntersect(hypernyms);
if (k <= 0) {
return requestedHyponyms;
}
TreeSet kPopularHyponyms = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
MaxPQ maxPQ = getWordWeightPQ(ngramMap, requestedHyponyms, startYear, endYear);
Iterator iterator = maxPQ.iterator();
int i = 0;
while (iterator.hasNext() && i < k) {
kPopularHyponyms.add(iterator.next().word());
i++;
}
return kPopularHyponyms;
}
private void addWordToMap(String word, Integer id) {
wordToIdsMap.addWordIdPair(word, id);
idToWordsMap.addIdWordPair(id, word);
}
private HashSet getWordIdSet(String word) {
return wordToIdsMap.get(word);
}
private HashSet getIdWordSet(int id) {
return idToWordsMap.get(id);
}
/**
* Sets both word to ids and ids to word mappings from the provided synsets.txt file
* @param fileName
*/
private void setMapsFromFile(String fileName) {
In in = new In(fileName);
ArrayList line;
int id;
while (in.hasNextLine()) {
line = Stream.of(in.readLine().split(",")).collect(Collectors.toCollection(ArrayList::new));
id = Integer.parseInt(line.get(0));
String[] words = (line.get(1)).trim().split("\\s+");
for (String word: words) {
addWordToMap(word, id);
}
}
}
/**
* Sets id to id mappings from the provided hyponyms.txt
* @param fileName
*/
private void setGraphFromFile(String fileName) {
In in = new In(fileName);
ArrayList line;
int parentId;
while (in.hasNextLine()) {
line = Stream.of(in.readLine().split(",")).collect(Collectors.toCollection(ArrayList::new));
parentId = Integer.parseInt(line.get(0));
for (int i = 1; i < line.size(); i++) {
int childId = Integer.parseInt(line.get(i));
graph.addNode(parentId, childId);
}
}
}
/**
* Returns a PQ of k amount of WordWeight objects - weight is based on their popularity in NgramMap
* between the given years
*/
private MaxPQ getWordWeightPQ(NGramMap nGramMap, Collection words, int startYear, int endYear) {
MaxPQ maxPQ = new MaxPQ<>();
for (String word : words) {
/*
* nMap - summedWHistory only takes lists as arg
* returns a timeseries year -> sum
* data() of timeseries returns the sums
* .stream().mapToDouble().sum() to get the total sum
*/
double weight = nGramMap.summedWeightHistory(Collections.singletonList(word), startYear, endYear)
.data()
.stream()
.mapToDouble(Double::doubleValue).sum();
WordWeight wordWeight = new WordWeight(word, weight);
maxPQ.insert(wordWeight);
}
return maxPQ;
}
}
```
### Class Graph
Unit Test:
```java
package ngordnet.main;
import java.util.HashSet;
public class Graph {
private IdToIdsMap idToIdsMap;
public Graph() {
idToIdsMap = new IdToIdsMap();
}
public void addNode(int parentId, int childId) {
idToIdsMap.addIdIdPair(parentId, childId);
}
public HashSet getNode(int parentId) {
return idToIdsMap.get(parentId);
}
/**
* Returns all children of the parent, not including the parent
* @param parentId
* @return
*/
public HashSet getAllChildren(int parentId) {
HashSet children = new HashSet<>();
if (getNode(parentId) != null) {
for (int childId: getNode(parentId)) {
children.addAll(getAllChildrenHelper(childId, children));
}
}
return children;
}
/**
* Recursively collects all children
* @param parentId
* @param children
*/
private HashSet getAllChildrenHelper(int parentId, HashSet children) {
children.add(parentId);
if (getNode(parentId) != null) {
for (int childId: getNode(parentId)) {
getAllChildrenHelper(childId, children);
}
}
return children;
}
}
```
### Class IdToIdsMap
No test, class used within [`Graph`](#class-graph) whose proper functionality is tested.
```java
package ngordnet.main;
import java.util.HashMap;
import java.util.HashSet;
public class IdToIdsMap extends HashMap {
public IdToIdsMap() {
super();
}
public void addIdIdPair(int parentId, int childId) {
HashSet childIdSet;
if (this.containsKey(parentId)) {
childIdSet = this.get(parentId);
childIdSet.add(childId);
return;
}
childIdSet = new HashSet<>();
childIdSet.add(childId);
this.put(parentId, childIdSet);
}
}
```
### Class WordToIdsMap
Unit test:
```java
package ngordnet.main;
import java.util.HashMap;
import java.util.HashSet;
/**
* LookUp of word associated with a set of ids (a word can have multiple ids, depending on its meaning in the WordNet)
*/
public class WordToIdsMap extends HashMap> {
public WordToIdsMap() {
super();
}
public void addWordIdPair(String word, Integer id) {
HashSet idSet;
if (this.containsKey(word)) {
idSet = this.get(word);
idSet.add(id);
return;
}
idSet = new HashSet<>();
idSet.add(id);
this.put(word, idSet);
}
@Override
public HashSet get(Object key) {
HashSet set = super.get(key);
if (set == null) {
set = new HashSet<>();
}
return set;
}
}
```
### Class IdToWordsMap
Unit test:
```java
package ngordnet.main;
import java.util.HashMap;
import java.util.HashSet;
public class IdToWordsMap extends HashMap> {
public IdToWordsMap() {
super();
}
public void addIdWordPair(Integer id, String word) {
HashSet wordSet;
if (this.containsKey(id)) {
wordSet = this.get(id);
wordSet.add(word);
return;
}
wordSet = new HashSet<>();
wordSet.add(word);
this.put(id, wordSet);
}
}
```
### Public record WordWeight
```java
package ngordnet.main;
public record WordWeight (String word, Double weight) implements Comparable{
@Override
public int compareTo(WordWeight wordWeight) {
return weight().compareTo(wordWeight.weight());
}
}
```
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://tomthestrom.gitbook.io/cs61b-fall-2022/project-2b-ngordnet-wordnet.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.